Kafka...
Kafka...
대체 넌 뭐늬??

독일계 성씨로 뜻은 갈까마귀라고 한다.. 아 이거 아니지

Kafka 공식 사이트를 들어가보았다.
an open-source distributed event streaming platform
open-source는 소스가 공개된 소프트웨어라는 뜻이고,
distributed는 분산처리
event는 어떤 사건
streaming은 실시간 처리를 말한다.
정리하자면, "실시간으로 발생하는 사건들을 분산처리 하는 소스코드가 공개된 플랫폼" 이라는 것이다.
여기서 몇가지 특성을 알수 있다.
카프카는
- 실시간
- 분산 처리
에 사용되어야 한다는 것이다.
카프카가 뭔지는 알겠다.
그럼 카프카는 왜 쓰게 되었고,
어떻게 써야 하는지 알아보자.
카프카 대체 넌 왜 태어났니?
공식사이트 introduction을 보니 어떤 푸근한 아저씨가 설명해주는 영상이 있다.
https://youtu.be/vHbvbwSEYGo?si=InYchicbP-ChixvK
음.. 이걸 봐도 뭔지 잘 모르겠다.
뭔가 여러 소스에서 발생하는 데이터 들을 실시간으로 destination(db 혹은 어떤 저장소)에 전달해주기 위해서 존재하는것 같다.
카프카의 탄생 배경
많이 알려졌다시피 카프카는 2011년경 링크드인에서 자체 개발한 서비스 이다.
그러니까 링크드인에서 어떠한 문제가 있었고 그 문제를 해결하기 위해 탄생한 것이다.
당시 링크드인은 어떤 문제가 있던 걸까?
2003년에 설립된 링크드인은 사용자가 많아짐과 동시에 생산되는 데이터도 기하급수적으로 늘어났을 것이다.
카프카가 만들어지기 전 기존의 데이터 파이프 라인은 end to end, 즉 데이터 소스로부터 data가 기록,저장 되는 destination까지 직통으로 연결되는 형태가 많았다.
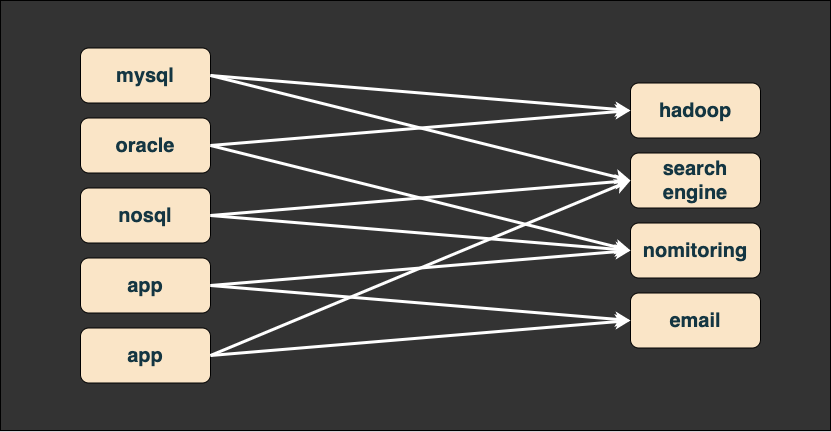
그러다 보니 자연스레 성능 및 유지보수 상의 문제가 많아진 것이다.
그렇기 때문에 이런 문제를 좀더 쉽게 해결하고자 data가 오가는 길목을 통합해야할 필요성이 생겼던 것이다.
그래서 도입된 것이 MOM (Message Oriented Middleware) 구조의 카프카 이다.

즉, 카프카는 MOM이다.
이런 방법으로 데이터를 주고 받을 때는 여러 장점이 있다.
1) 느슨한 결합(decoupling) : 데이터 발신자와 수신자가 직접 연결되지 않으므로 의존성이 떨어진다. 의존성이 떨어지면 어느 한쪽에 문제가 생기더라도 연속적인 문제가 발생하는 것을 막을 수 있다.
2) 확장가능성 (scalable) : 또한 발신자와 수신자가 직접 연결되지 않으므로 수신자와 발신자를 필요에 따라 추가할 수 있다.
3) 보장성 (guarantees) : 발신자로부터 발생한 메세지가 중개자에 저장이 되므로 수신자 측에서 일시적인 오류가 발생하더라도 오류가 해결된 뒤에 수신하지 못했던 메세지(데이터) 를 받을 수 있다.
4) 비동기 통신 (asynchronous) : 이것을 이해하기 위해서는 동기와 비동기적 처리에 대한 이해가 필요한데, 간략하게 설명하면 이렇다. 동기적 통신을 한다면 수신자 측에서 발신자에 어떤 요청을 했을경우 그 요청에 해당하는 작업이 모두 끝날때까지 수신자는 다른 작업을 수행할 수 없다. 왜냐하면 동기적 통신은 요청과 요청을 받는 작업에 수신자가 온전히 할당되기 때문이다. 그렇기 때문에 이미지파일과 같이 비교적 크기가 큰 데이터에 대한 처리가 비효율적이다. 그러나 비동기 통신은 다르다. 수신자 측에서 어떤 요청을 한다 하더라도 그 요청된 작업이 수행되는 동안 다른 작업을 할 수 있다. 카프카와 같은 중개자가 생기면서 이런 프로세스를 가능하게 하는 것이다.
MOM의 모델
MOM은 크게 두가지 모델을 갖는다.
하나는 P2P (Point to Point) 이고, 다른 하나는 Pub/Sub 이다.
두 모델의 가장 큰 차이점은 1:1이냐, N:M이냐 하는것이다.
P2P는 1:1로 고정이고, Pub/Sub 모델은 N:M으로 다수의 데이터 발신자와 수신자가 연결될 수 있다.
그래서 카프카는 MOM이면서, 다대다 관계를 갖을수 있는 Pub/Sub 모델인 것이다.
카프카의 등장 전과 후
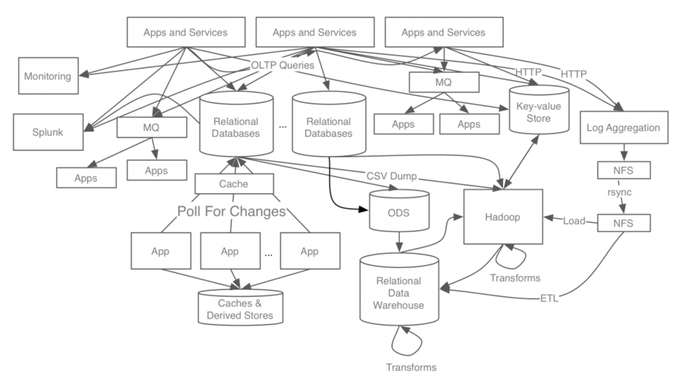
위 그림은 카프카를 사용하기 이전의 링크드인의 실제 아키텍처이다.
이렇게 어떤 문제가 발생해도 문제의 원인을 찾기 힘들고 연속적인 문제가 발생할것 같았던 복잡한 구조가 아래와 같이 바뀐것이다.
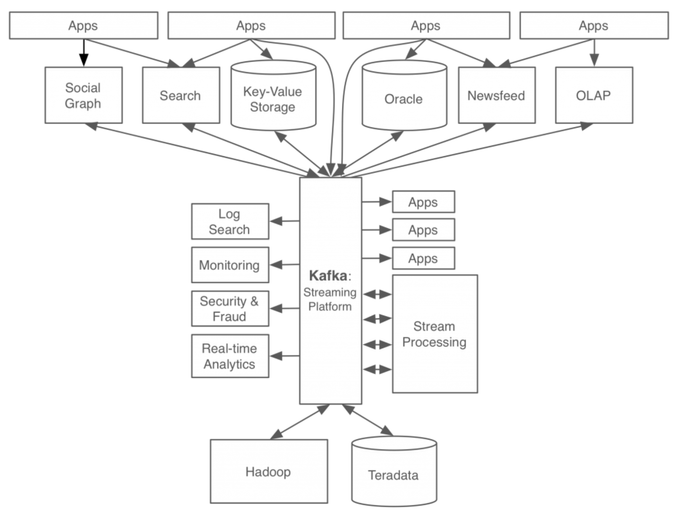
한눈에 보아도 데이터가 오고가는 통로를 통합함으로써 구조가 단순해진것을 볼 수 있다.
이로써 카프카의 등장배경과 효과 등에 대해서 정리해보았다.
다음 시간에는 카프카의 특징과 그것을 구현하기 위해 도입된 개념들에 대해서 정리해볼것이다.
그리고 실제 사용방법은 어떠한지 또한 정리해봐야겠다.
참고
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
https://hudi.blog/what-is-kafka/
카프카가 무엇이고, 왜 사용하는 것 일까?
메시지 큐와 MOM 출처: https://www.cloudamqp.com/blog/what-is-message-queuing.html 카프카를 이해하기 위해서는 메시지 큐와 MOM을 먼저 알아야한다. 메시지 큐는 분산화된 환경에서 발신자와 수신자 사이에서
hudi.blog
카프카 설치 에러 정리
https://kafka.apache.org/downloads 에서 원하는 버전 골라서 설치 1. exec: java: not found 오류발생 binding to port 0.0.0.0/0.0.0.0:2181 오류 해결 2. Native memory alloc
velog.io
https://saramin.github.io/2019-09-17-kafka/
kafka 설정을 사용한 문제해결
안녕하세요. 사람인HR 기술연구소 서비스인프라개발팀 안경민입니다. 메일 시스템 구조개선을 진행하면서 kafka를 사용하며 부딪혔던 문제와 해결했던 방법을 공유하여 같은 문제를 겪을 수 있
saramin.github.io
https://gymcoding.github.io/2020/09/16/kafka-what/
아파치 카프카(1) - 이해하기 | GYMCODING
들어가며 2020년 9월 최근 ThingsBoard 오픈소스 플랫폼 기반의 IoT 데이터 수집 및 시각화 프로젝트를 맡게되었다. 프로젝트 업무 중 디바이스로부터 데이터를 수집하는 구간인 ThingsBoard IoT Gateway 에
gymcoding.github.io
'Road to data engineer' 카테고리의 다른 글
| hbase 설치하는라 반나절 날린 썰... (0) | 2023.09.03 |
|---|---|
| 프로젝트 준비3 : EC2로 mysql 배포하기 (0) | 2023.08.28 |
| 프로젝트 준비2 : EC2 instance에서 파이썬 프로그램을 실행하기 위한 가상환경 세팅 방법 (0) | 2023.08.28 |
| 프로젝트 준비1 : ML model(feat. iris dataset) flask로 웹 배포하기 (0) | 2023.08.25 |
| 객체지향 언어 이제 끝2 (0) | 2023.08.23 |


